eurlex: Retrieve data on European Union law in R
Source:vignettes/articles/eurlexpkg.Rmd
eurlexpkg.RmdThis vignette shows how to use the eurlex R package to
retrieve data on European Union law.
Introduction
Dozens of political scientists and legal scholars use data on
European Union laws in their research. The provenance of these data is
rarely discussed. More often than not, researchers resort to the quick
and dirty technique of scraping entire html pages from
eur-lex.europa.eu. This is not the optimal, nor preferred
(from the perspective of the server host) approach of retrieving data,
however, especially as the Publication Office of the European Union, the
public body behind Eur-Lex, operates several dedicated APIs for
automated retrieval of its data.
The allure of web scraping is completely understandable. Not only is it easier to download data that can be readily seen in a user-friendly manner through a browser, using the dedicated APIs requires technical knowledge of semantic web and Client URL technologies, which is not necessarily widespread among researchers. And why go through the pain of learning how to compile SPARQL queries when it is much easier to simply download the web page?
The eurlex R package attempts to significantly reduce
the overhead associated with using the SPARQL and REST APIs made
available by the EU Publication Office. Although at present it does not
offer access to the same array of information as comprehensive web
scraping might, the package provides simpler, more efficient and
transparent access to data on European Union law. This vignette gives a
quick guide to the package and an even quicker introduction to the
Eur-Lex dataverse.
The eurlex package
The eurlex package currently envisions the typical
use-case to consist of getting bulk information about EU law and policy
into R as fast as possible. The package contains three core functions to
achieve that objective: elx_make_query() to create SPARQL
queries based on user input; elx_run_query() to execute the
pre-made or any other manually input query; and
elx_fetch_data() to fire GET requests for certain metadata
to the REST API.
More advanced users might be interested in downloading and
custom-parsing XML notices with elx_download_xml().
elx_make_query(): Generate SPARQL queries
The function elx_make_query takes as its first argument
the type of resource to be retrieved from the semantic database that
powers Eur-Lex (and other publications) called Cellar.
library(eurlex)
library(dplyr)
query_dir <- elx_make_query(resource_type = "directive")Currently, it is possible to choose from among a host of resource types, including directives, regulations and even case law (see function description for the full list). It is also possible to manually specify a resource type from the eligible list.1
The choice of resource type is then reflected in the SPARQL query generated by the function:
query_dir %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex where{ ?work cdm:work_has_resource-type ?type. FILTER(?type=<http://publications.europa.eu/resource/authority/resource-type/DIR>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/DIR_IMPL>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/DIR_DEL>)
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }
elx_make_query(resource_type = "caselaw") %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex where{ ?work cdm:work_has_resource-type ?type. FILTER(?type=<http://publications.europa.eu/resource/authority/resource-type/JUDG>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/ORDER>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/OPIN_JUR>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/THIRDPARTY_PROCEED>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/GARNISHEE_ORDER>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RULING>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/JUDG_EXTRACT>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/INFO_JUDICIAL>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/VIEW_AG>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/OPIN_AG>)
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }
elx_make_query(resource_type = "manual", manual_type = "SWD") %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex where{ ?work cdm:work_has_resource-type ?type.FILTER(?type=<http://publications.europa.eu/resource/authority/resource-type/SWD>)
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }There are various ways of querying the same information in the Cellar database due to the existence of several overlapping classes and identifiers describing the same resources. The queries generated by the function should offer a reliable way of obtaining exhaustive results, as they have been validated by the helpdesk of the Publication Office. At the same time, it is always possible there will be issues either on the query or the database side; please report any you encounter through Github.
The other arguments in elx_make_query() relate to
additional metadata to be returned. The results include by default the
CELEX
number and exclude corrigenda (corrections of errors in
legislation). Other data needs to be opted into. Make sure to select
ones that are logically compatible (e.g. case law does not have a legal
basis). More options should be added in the future.
Note that availability of data for each variable might have an impact on the results. The data frame returned by the query might be shrunken to the size of the variable with most missing data. It is recommended to always compare results from a desired query to a minimal query requesting only celex ids.
# minimal query: elx_make_query(resource_type = "directive")
elx_make_query(resource_type = "directive", include_date = TRUE, include_force = TRUE) %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex ?date ?force where{ ?work cdm:work_has_resource-type ?type. FILTER(?type=<http://publications.europa.eu/resource/authority/resource-type/DIR>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/DIR_IMPL>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/DIR_DEL>)
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} OPTIONAL{?work cdm:work_date_document ?date.} OPTIONAL{?work cdm:resource_legal_in-force ?force.} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }
# minimal query: elx_make_query(resource_type = "recommendation")
elx_make_query(resource_type = "recommendation", include_date = TRUE, include_lbs = TRUE) %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex ?date ?lbs ?lbcelex ?lbsuffix where{ ?work cdm:work_has_resource-type ?type. FILTER(?type=<http://publications.europa.eu/resource/authority/resource-type/RECO>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_DEC>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_DIR>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_OPIN>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_RES>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_REG>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_RECO>||
#> ?type=<http://publications.europa.eu/resource/authority/resource-type/RECO_DRAFT>)
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} OPTIONAL{?work cdm:work_date_document ?date.} OPTIONAL{?work cdm:resource_legal_based_on_resource_legal ?lbs.
#> ?lbs cdm:resource_legal_id_celex ?lbcelex.
#> OPTIONAL{?bn owl:annotatedSource ?work.
#> ?bn owl:annotatedProperty <http://publications.europa.eu/ontology/cdm#resource_legal_based_on_resource_legal>.
#> ?bn owl:annotatedTarget ?lbs.
#> ?bn annot:comment_on_legal_basis ?lbsuffix}} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }You can also decide to not specify any resource types, in which case all types of documents will be returned. As there are over a million documents with a CELEX identifier, this is likely not efficient for a majority of users. But since version 0.3.5 it is possible to request documents belonging to a particular “sector” or directory code.
# request documents from directory 18 ("Common Foreign and Security Policy")
# and sector 3 ("Legal acts")
elx_make_query(resource_type = "any",
directory = "18",
sector = 3) %>%
cat()
#> PREFIX cdm: <http://publications.europa.eu/ontology/cdm#>
#> PREFIX annot: <http://publications.europa.eu/ontology/annotation#>
#> PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
#> PREFIX dc:<http://purl.org/dc/elements/1.1/>
#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#> PREFIX owl:<http://www.w3.org/2002/07/owl#>
#> select distinct ?work ?type ?celex where{
#> VALUES (?value)
#> { (<http://publications.europa.eu/resource/authority/fd_555/18>)
#> (<http://publications.europa.eu/resource/authority/dir-eu-legal-act/18>)
#> }
#> {?work cdm:resource_legal_is_about_concept_directory-code ?value.
#> }
#> UNION
#> {?work cdm:resource_legal_is_about_concept_directory-code ?directory.
#> ?value skos:narrower+ ?directory.
#> }
#>
#> ?work cdm:resource_legal_id_sector ?sector.
#> FILTER(str(?sector)='3')
#>
#> FILTER not exists{?work cdm:work_has_resource-type <http://publications.europa.eu/resource/authority/resource-type/CORRIGENDUM>} OPTIONAL{?work cdm:resource_legal_id_celex ?celex.} FILTER not exists{?work cdm:do_not_index "true"^^<http://www.w3.org/2001/XMLSchema#boolean>}. }Now that we have a query, we are ready to run it.
elx_run_query(): Execute SPARQL queries
elx_run_query() sends SPARQL queries to a pre-specified
endpoint. The function takes the query string as the main argument,
which means you can manually pass it any working SPARQL query (relevant
to official EU publications).
results <- elx_run_query(query = query_dir)
# the functions are compatible with piping
#
# elx_make_query("directive") %>%
# elx_run_query()
head(results)
#> work type celex
#> 1 0d76f53e-267f-495c-9854-15e8c3ee05c5 DIR 31965L0066
#> 6 47ba284d-04b9-11e3-a352-01aa75ed71a1 DIR 32013L0038
#> 11 899b6c44-84ec-11e4-91cd-01aa75ed71a1 DIR 32014L0107
#> 16 931d7a62-e01e-4f41-a318-a048818fc71d DIR 31985L0346
#> 21 9e1d16c5-8aef-42ee-874c-283a182c49a9 DIR 31974L0394
#> 26 a5d0648f-2957-11e6-b616-01aa75ed71a1 DIR 32016L0882The function outputs a data.frame where each column
corresponds to one of the requested variables, while the rows accumulate
observations of the resource type satisfying the query criteria.
Obviously, the more data is to be returned, the longer the execution
time, varying from a few seconds to several minutes, depending also on
your connection.
The first column always contains the unique URI of a “work” (legislative act or court judgment) which identifies each resource in Cellar. Several human-readable identifiers are normally associated with each “work” but the most useful one is CELEX, retrieved by default.2
One column you should always pay attention to is type
(as in resource_type). The URIs contained there reflect the
FILTER argument in the SPARQL query, which is manually pre-specified.
All resources are indexed as being of one type or another. For example,
when retrieving directives, the results are going to return also
delegated directives, which might not be desirable, depending on your
needs. You can filter results by type to make the necessary
adjustments. The queries are expansive by default in the spirit of
erring on the side of over-inclusiveness rather than vice versa.
head(results$type,5)
#> [1] "DIR" "DIR" "DIR" "DIR" "DIR"
results %>%
distinct(type)
#> type
#> 1 DIR
#> 2 DIR_DEL
#> 3 DIR_IMPLThe data is returned in the long format, which means that rows are
recycled up to the length of the variable with the most data points. For
example, if 20 directives are returned, each with two legal bases, the
resulting data.frame will have 40 rows. Some variables,
such as dates, contain unexpectedly several entries for some documents.
You should always check the number of unique identifiers in the results
instead of assuming that each row is a unique observation.
EuroVoc descriptors
EuroVoc is a multilingual thesaurus, keywords from which are used to describe the content of European Union documents. Most resource types that can be retrieved with the pre-defined queries in this package can be accompanied by EuroVoc keywords and these can be retrieved as other variables.
rec_eurovoc <- elx_make_query("recommendation", include_eurovoc = TRUE, limit = 10) %>%
elx_run_query() # truncated results for sake of the example
rec_eurovoc %>%
select(celex, eurovoc)
#> celex eurovoc
#> 1 52002SC1118 http://eurovoc.europa.eu/1018
#> 5 52016PC0294 http://eurovoc.europa.eu/1018
#> 9 52007SC0621 http://eurovoc.europa.eu/1018
#> 13 52015PC0243 http://eurovoc.europa.eu/1018
#> 17 52008SC0572 http://eurovoc.europa.eu/1018
#> 21 52016PC0293 http://eurovoc.europa.eu/1018
#> 25 52008SC0571 http://eurovoc.europa.eu/1018
#> 29 51991PC0494 http://eurovoc.europa.eu/1102
#> 33 52016PC0517 http://eurovoc.europa.eu/1018
#> 37 52008SC2011 http://eurovoc.europa.eu/1018By default, the endpoint returns the EuroVoc concept codes rather
than the labels (keywords). The function
elx_label_eurovoc() needs to be called to obtain a look-up
table with the labels.
eurovoc_lookup <- elx_label_eurovoc(uri_eurovoc = rec_eurovoc$eurovoc)
print(eurovoc_lookup)
#> eurovoc labels
#> 1 http://eurovoc.europa.eu/1018 public finance
#> 3 http://eurovoc.europa.eu/1102 cheeseThe results include labels only for unique identifiers, but with
dplyr::left_join() it is straightforward to append the
labels to the entire dataset.
rec_eurovoc %>%
left_join(eurovoc_lookup)
#> Joining with `by = join_by(eurovoc)`
#> work type celex
#> 1 db3c2cd0-d78e-4c60-a942-6e88df7fe4b3 RECO_DEC 52002SC1118
#> 2 88e6faca-4450-11e6-9c64-01aa75ed71a1 RECO_DEC 52016PC0294
#> 3 3a5c2cfe-52c9-41d5-ad59-4e1a8da29f0f RECO_DEC 52007SC0621
#> 4 5899347a-f951-11e4-a4c8-01aa75ed71a1 RECO_DEC 52015PC0243
#> 5 66b3f9ab-cb63-4c56-a122-948a1425ab27 RECO_DEC 52008SC0572
#> 6 5d433748-444f-11e6-9c64-01aa75ed71a1 RECO_DEC 52016PC0293
#> 7 6b79f264-5bc6-4301-904f-ba813557de67 RECO_DEC 52008SC0571
#> 8 95b58211-8885-421c-92c4-ee48fb954a8e RECO_DEC 51991PC0494
#> 9 6e14fc24-54ed-11e6-89bd-01aa75ed71a1 RECO_DEC 52016PC0517
#> 10 9a092f33-2660-4ed2-b90f-4c86ba85fde1 RECO_DEC 52008SC2011
#> eurovoc labels
#> 1 http://eurovoc.europa.eu/1018 public finance
#> 2 http://eurovoc.europa.eu/1018 public finance
#> 3 http://eurovoc.europa.eu/1018 public finance
#> 4 http://eurovoc.europa.eu/1018 public finance
#> 5 http://eurovoc.europa.eu/1018 public finance
#> 6 http://eurovoc.europa.eu/1018 public finance
#> 7 http://eurovoc.europa.eu/1018 public finance
#> 8 http://eurovoc.europa.eu/1102 cheese
#> 9 http://eurovoc.europa.eu/1018 public finance
#> 10 http://eurovoc.europa.eu/1018 public financeAs elsewhere in the API, we can tap into the multilingual nature of EU documents also when it comes to the EuroVoc keywords. Moreover, most concepts in the thesaurus are associated with alternative labels; these can be returned as well (separated by a comma).
eurovoc_lookup <- elx_label_eurovoc(uri_eurovoc = rec_eurovoc$eurovoc,
alt_labels = TRUE,
language = "sk")
rec_eurovoc %>%
left_join(eurovoc_lookup) %>%
select(celex, eurovoc, labels)
#> Joining with `by = join_by(eurovoc)`
#> celex eurovoc labels
#> 1 52002SC1118 http://eurovoc.europa.eu/1018 verejné financie
#> 2 52016PC0294 http://eurovoc.europa.eu/1018 verejné financie
#> 3 52007SC0621 http://eurovoc.europa.eu/1018 verejné financie
#> 4 52015PC0243 http://eurovoc.europa.eu/1018 verejné financie
#> 5 52008SC0572 http://eurovoc.europa.eu/1018 verejné financie
#> 6 52016PC0293 http://eurovoc.europa.eu/1018 verejné financie
#> 7 52008SC0571 http://eurovoc.europa.eu/1018 verejné financie
#> 8 51991PC0494 http://eurovoc.europa.eu/1102 syr
#> 9 52016PC0517 http://eurovoc.europa.eu/1018 verejné financie
#> 10 52008SC2011 http://eurovoc.europa.eu/1018 verejné financie
elx_fetch_data(): Fire GET requests
A core contribution of the SPARQL requests is that we obtain a
comprehensive list of identifiers that we can subsequently use to obtain
more data relating to the document in question. While the results of the
SPARQL queries are useful also for webscraping (with the
rvest package), the function elx_fetch_data()
enables us to fire GET requests to retrieve data on documents with known
identifiers (including Cellar URI).
One of the most sought-after data in the Eur-Lex dataverse is the text. It is possible now to automate the pipeline for downloading html and plain texts from Eur-Lex. Similarly, you can retrieve the title of the document. For both you can specify also the desired language (English by default). Other metadata might be added in the future.
# the function is not vectorized by default
# elx_fetch_data(url = results$work[1], type = "title")
# we can use purrr::map() to play that role
library(purrr)
# wrapping in possibly() would catch errors in case there is a server issue
dir_titles <- results[1:5,] %>% # take the first 5 directives only to save time
mutate(work = paste("http://publications.europa.eu/resource/cellar/", work, sep = "")) |>
mutate(title = map_chr(work, possibly(elx_fetch_data, otherwise = NA_character_),
"title")) %>%
select(celex, title)
print(dir_titles)
#> celex
#> 1 31965L0066
#> 6 32013L0038
#> 11 32014L0107
#> 16 31985L0346
#> 21 31974L0394
#> title
#> 1 Council Directive 65/66/EEC of 26 January 1965 laying down specific criteria of purity for preservatives authorised for use in foodstuffs intended for human consumption
#> 6 Directive 2013/38/EU of the European Parliament and of the Council of 12 August 2013 amending Directive 2009/16/EC on port State control Text with EEA relevance
#> 11 Council Directive 2014/107/EU of 9 December 2014 amending Directive 2011/16/EU as regards mandatory automatic exchange of information in the field of taxation
#> 16 Council Directive 85/346/EEC of 8 July 1985 amending Directive 83/181/EEC determining the scope of Article 14 (1) (d) of Directive 77/388/EEC as regards exemption from value added tax on the final importation of certain goods
#> 21 Council Directive 74/394/EEC of 22 July 1974 making a tenth amendment to Directive No 64/54/EEC on the approximation of the laws of the Member States concerning the preservatives authorized for use in foodstuffs intended for human consumptionNote that text requests are by far the most time-intensive; requesting the full text for thousands of documents is liable to extend the run-time into hours. Texts are retrieved from html by priority, but methods for .pdfs and .docs are also implemented.3 The function even handles multi-document resources (by pasting them together).
Application
In this section I showcase a simple application of
eurlex on making overviews of EU legislation. First, we
collate data on directives.
dirs <- elx_make_query(resource_type = "directive", include_date = TRUE, include_force = TRUE) %>%
elx_run_query()Let’s calculate the proportion of directives currently in force in the entire set of directives ever adopted. This variable offers a particularly good demonstration of the usefulness of the package to retrieve EU law data, because it changes every day, as new acts enter into force and old ones drop out. Regularly scraping webpages for this purpose and scale is simply impractical and disproportional.
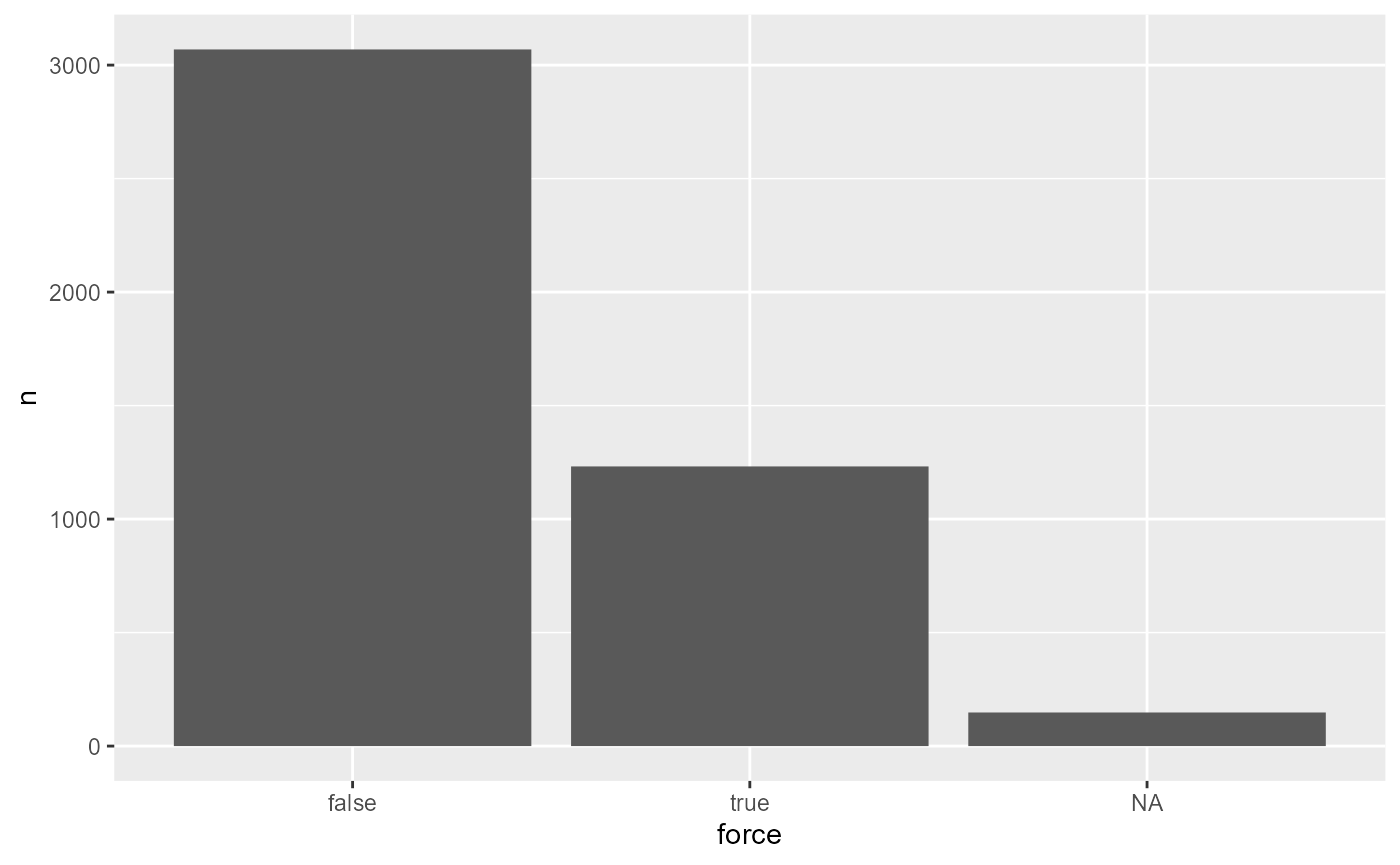
Directives become naturally outdated with time. It might be all the more interesting to see which older acts are thus still surviving.
dirs %>%
filter(!is.na(force)) %>%
mutate(date = as.Date(date)) %>%
ggplot(aes(x = date, y = celex)) +
geom_point(aes(color = force), alpha = 0.1) +
theme(axis.text.y = element_blank(),
axis.line.y = element_blank(),
axis.ticks.y = element_blank())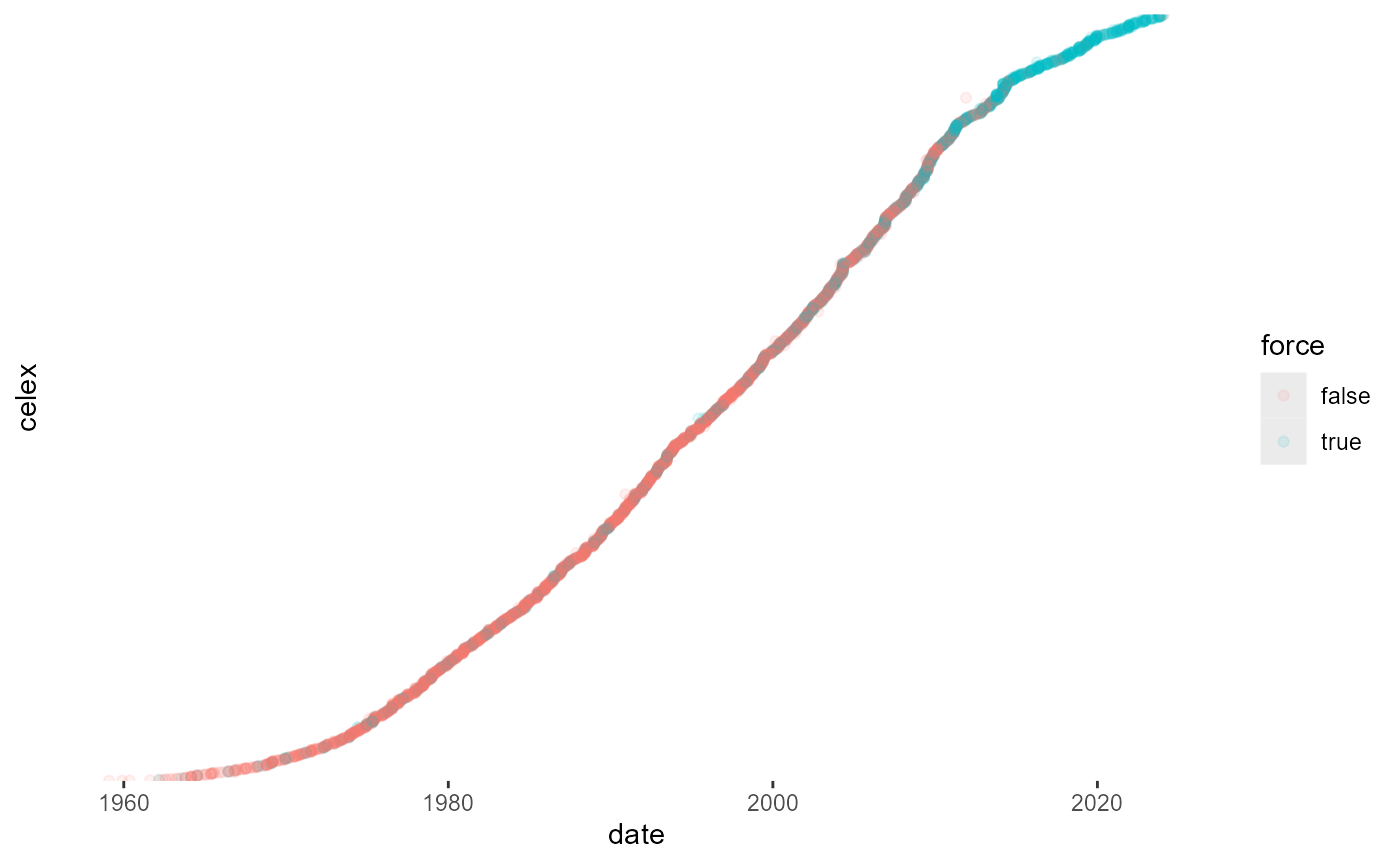
We want to know a bit more about some directives from the early 1970s that are still in force today. Their titles could give us a clue.
dirs_1970_title <- dirs %>%
filter(between(as.Date(date), as.Date("1970-01-01"), as.Date("1973-01-01")),
force == "true") %>%
mutate(work = paste("http://publications.europa.eu/resource/cellar/", work, sep = "")) |>
mutate(title = map_chr(work, possibly(elx_fetch_data, otherwise = NA_character_),
"title"))
print(dirs_1970_title)
#> work
#> 1 http://publications.europa.eu/resource/cellar/675f4ee1-be6f-4d60-b062-87d8deef23be
#> 2 http://publications.europa.eu/resource/cellar/c9c0e382-b55c-4bd5-9a02-d616e80eb4b1
#> 3 http://publications.europa.eu/resource/cellar/dac7b9d9-a3b3-448d-9747-18f842cbe930
#> 4 http://publications.europa.eu/resource/cellar/f1470a0a-489a-48b8-8fd4-4162abce1481
#> 5 http://publications.europa.eu/resource/cellar/0960fa20-bda1-40ef-832f-99788c7d0271
#> 6 http://publications.europa.eu/resource/cellar/bca01e38-d764-4f2d-b96b-4962979326dd
#> 7 http://publications.europa.eu/resource/cellar/c7b98d2f-948e-4d87-85e6-0228021c752d
#> 8 http://publications.europa.eu/resource/cellar/a82fea91-74c7-4a6b-9b33-3135073f0d65
#> 9 http://publications.europa.eu/resource/cellar/2a022c3d-9a2c-45a8-95e9-076a4f0bf5de
#> 10 http://publications.europa.eu/resource/cellar/4100178a-846e-432d-b8d4-6400f9fc6465
#> type celex date force
#> 1 DIR 31972L0160 1972-04-17 true
#> 2 DIR 31972L0159 1972-04-17 true
#> 3 DIR 31972L0161 1972-04-17 true
#> 4 DIR 31972L0418 1972-12-06 true
#> 5 DIR 31972L0274 1972-07-20 true
#> 6 DIR 31971L0162 1971-03-30 true
#> 7 DIR 31970L0157 1970-02-06 true
#> 8 DIR 31971L0086 1971-02-01 true
#> 9 DIR 31972L0221 1972-06-06 true
#> 10 DIR 31971L0140 1971-03-22 true
#> title
#> 1 Council Directive 72/160/EEC of 17 April 1972 concerning measures to encourage the cessation of farming and the reallocation of utilized agricultural area for the purposes of structural improvement
#> 2 Council Directive 72/159/EEC of 17 April 1972 on the modernization of farms
#> 3 Council Directive 72/161/EEC of 17 April 1972 concerning the provision of socio-economic guidance for and the acquisition of occupational skills by persons engaged in agriculture
#> 4 Council Directive 72/418/EEC of 6 December 1972 amending the Directives of 14 June 1966 on the marketing of beet seed, of fodder-crop seed, of cereal seed, of seed potatoes, the Directive of 30 June 1969 on the marketing of oleaginous and fibrous plant seed, and the Directives of 29 September 1970 on the marketing of vegetable seed and on the Common Catalogue of Varieties of Agricultural Plant Species
#> 5 Council Directive 72/274/EEC of 20 July 1972 amending the Directives of 14 June 1966 on the marketing of beet seed, fodder plant seed, cereal seed, seed potatoes, the Directive of 30 June 1969 on the marketing of seed of oil and fibre plants and the Directives of 29 September 1970 on the marketing of vegetable seed and on the common catalogue of varieties of agricultural species
#> 6 Council Directive of 30 March 1971 amending the Directives of 14 June 1966 on the marketing of beet seed, fodder plant seed, cereal seed and seed potatoes, the Directive of 30 June 1969 on the marketing of seed of oil and fibre plants and the Directive of 29 September 1970 on the marketing of vegetable seed
#> 7 Council Directive 70/157/EEC of 6 February 1970 on the approximation of the laws of the Member States relating to the permissible sound level and the exhaust system of motor vehicles
#> 8 Council Directive 71/86/EEC of 1 February 1971 on harmonisation of the basic provisions in respect of guarantees for short-term transactions (political risks) with public buyers or with private buyers
#> 9 Council Directive 72/221/EEC of 6 June 1972 concerning coordinated annual surveys of industrial activity
#> 10 Council Directive 71/140/EEC of 22 March 1971 amending the Directive of 9 April 1968 on the marketing of material for the vegetative propagation of the vineI will use the tidytext package to get a quick idea of
what the legislation is about by visualizing the most distinctive words
in the titles.
library(tidytext)
# calculate tf-idf and plot top words
dirs_1970_title %>%
select(celex, title) %>%
unnest_tokens(word, title) %>%
count(celex, word, sort = TRUE) %>%
filter(!grepl("\\d", word)) %>%
bind_tf_idf(word, celex, n) %>%
slice_max(tf_idf, n = 15) %>%
ggplot(aes(x = reorder(word, tf_idf), y = tf_idf)) +
geom_col() +
coord_flip() +
labs(x = NULL, y = "TF-IDF", title = "Top words in directive titles (1970-1973)")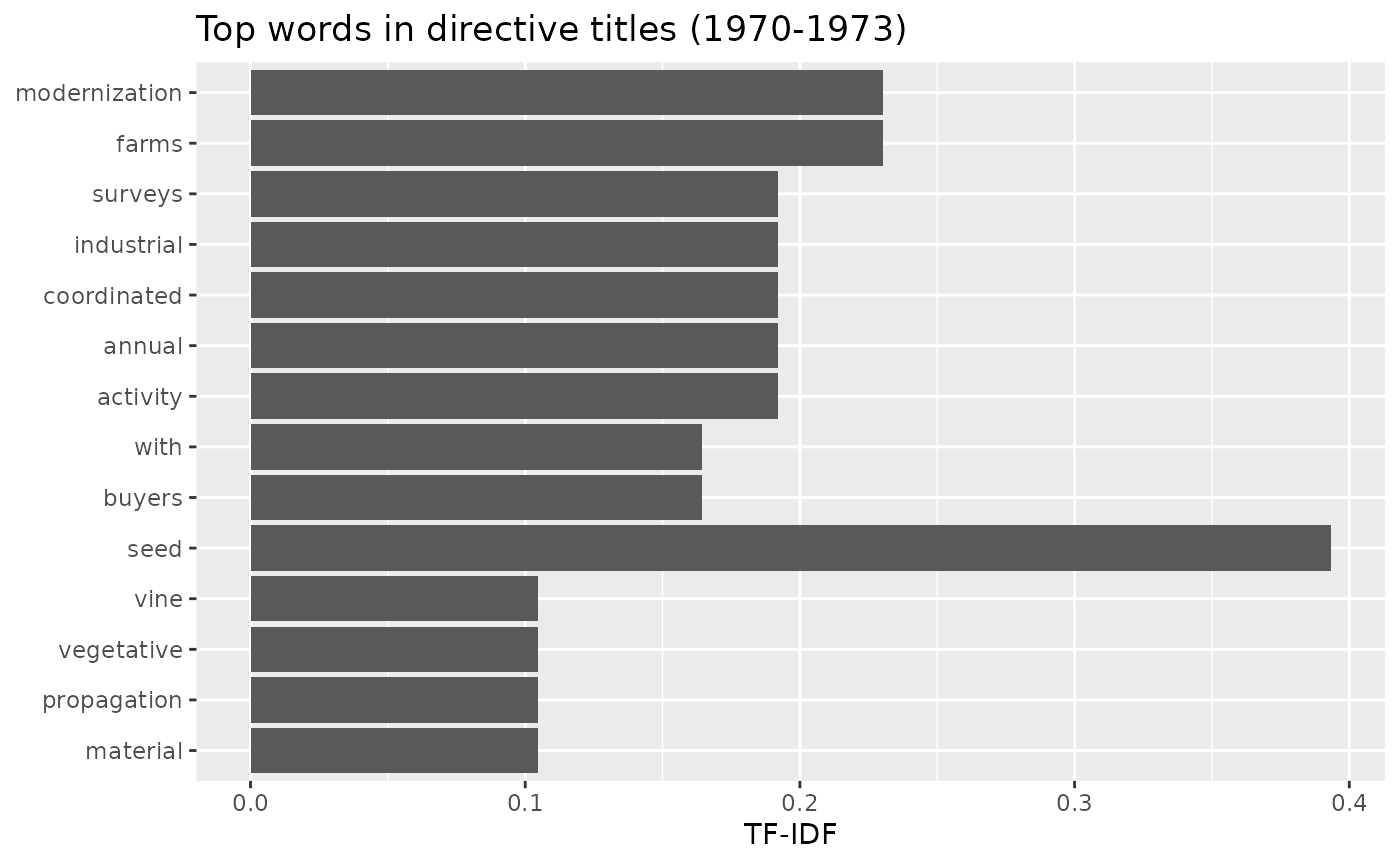
I use term-frequency inverse-document frequency (tf-idf) to weight the importance of the words. This down-weights common words like “the” and “and” that convey little meaning, highlighting instead the more distinctive terms.
This is an extremely basic application of the eurlex
package. Much more sophisticated methods can be used to analyse both the
content and metadata of European Union legislation. If the package is
useful for your research, please cite the accompanying
paper.4